CCA-500 | Top Tips Of Updated CCA-500 Test
Accurate of CCA-500 exam materials and testing software for Cloudera certification for IT learners, Real Success Guaranteed with Updated CCA-500 pdf dumps vce Materials. 100% PASS Cloudera Certified Administrator for Apache Hadoop (CCAH) exam Today!
Online CCA-500 free questions and answers of New Version:
NEW QUESTION 1
Which YARN daemon or service monitors a Controller’s per-application resource using (e.g., memory CPU)?
- A. ApplicationMaster
- B. NodeManager
- C. ApplicationManagerService
- D. ResourceManager
Answer: A
NEW QUESTION 2
You observed that the number of spilled records from Map tasks far exceeds the number of map output records. Your child heap size is 1GB and your io.sort.mb value is set to 1000MB. How would you tune your io.sort.mb value to achieve maximum memory to disk I/O ratio?
- A. For a 1GB child heap size an io.sort.mb of 128 MB will always maximize memory to disk I/O
- B. Increase the io.sort.mb to 1GB
- C. Decrease the io.sort.mb value to 0
- D. Tune the io.sort.mb value until you observe that the number of spilled records equals (or is as close to equals) the number of map output records.
Answer: D
NEW QUESTION 3
You want to understand more about how users browse your public website. For example, you want to know which pages they visit prior to placing an order. You have a server farm of 200 web servers hosting your website. Which is the most efficient process to gather these web server across logs into your Hadoop cluster analysis?
- A. Sample the web server logs web servers and copy them into HDFS using curl
- B. Ingest the server web logs into HDFS using Flume
- C. Channel these clickstreams into Hadoop using Hadoop Streaming
- D. Import all user clicks from your OLTP databases into Hadoop using Sqoop
- E. Write a MapReeeduce job with the web servers for mappers and the Hadoop cluster nodes for reducers
Answer: B
Explanation:
Apache Flume is a service for streaming logs into Hadoop.
Apache Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of streaming data into the Hadoop Distributed File System (HDFS). It has a simple and flexible architecture based on streaming data flows; and is robust and fault tolerant with tunable reliability mechanisms for failover and recovery.
NEW QUESTION 4
You are running a Hadoop cluster with a NameNode on host mynamenode. What are two ways to determine available HDFS space in your cluster?
- A. Run hdfs fs –du / and locate the DFS Remaining value
- B. Run hdfs dfsadmin –report and locate the DFS Remaining value
- C. Run hdfs dfs / and subtract NDFS Used from configured Capacity
- D. Connect to http://mynamenode:50070/dfshealth.jsp and locate the DFS remaining value
Answer: B
NEW QUESTION 5
Cluster Summary:
45 files and directories, 12 blocks = 57 total. Heap size is 15.31 MB/193.38MB(7%)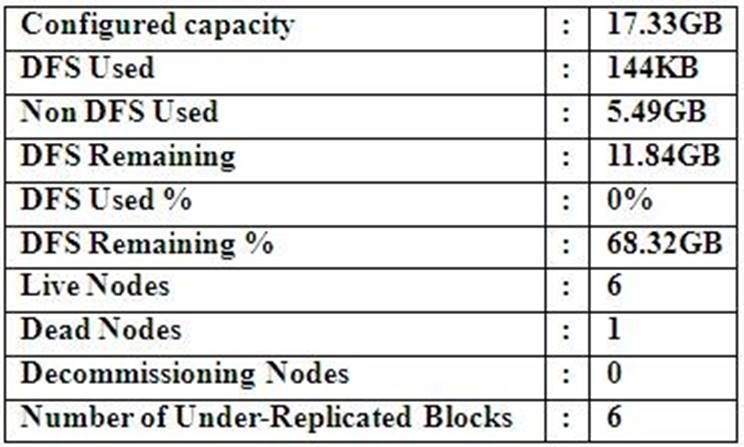
Refer to the above screenshot.
You configure a Hadoop cluster with seven DataNodes and on of your monitoring UIs displays the details shown in the exhibit.
What does the this tell you?
- A. The DataNode JVM on one host is not active
- B. Because your under-replicated blocks count matches the Live Nodes, one node is dead, and your DFS Used % equals 0%, you can’t be certain that your cluster has all the data you’ve written it.
- C. Your cluster has lost all HDFS data which had bocks stored on the dead DatNode
- D. The HDFS cluster is in safe mode
Answer: A
NEW QUESTION 6
Which two features does Kerberos security add to a Hadoop cluster?(Choose two)
- A. User authentication on all remote procedure calls (RPCs)
- B. Encryption for data during transfer between the Mappers and Reducers
- C. Encryption for data on disk (“at rest”)
- D. Authentication for user access to the cluster against a central server
- E. Root access to the cluster for users hdfs and mapred but non-root access for clients
Answer: AD
NEW QUESTION 7
You have recently converted your Hadoop cluster from a MapReduce 1 (MRv1) architecture to MapReduce 2 (MRv2) on YARN architecture. Your developers are accustomed to specifying map and reduce tasks (resource allocation) tasks when they run jobs: A developer wants to know how specify to reduce tasks when a specific job runs. Which method should you tell that developers to implement?
- A. MapReduce version 2 (MRv2) on YARN abstracts resource allocation away from the idea of “tasks” into memory and virtual cores, thus eliminating the need for a developer to specify the number of reduce tasks, and indeed preventing the developer from specifying the number of reduce tasks.
- B. In YARN, resource allocations is a function of megabytes of memory in multiples of 1024m
- C. Thus, they should specify the amount of memory resource they need by executing –D mapreduce-reduces.memory-mb-2048
- D. In YARN, the ApplicationMaster is responsible for requesting the resource required for a specific launc
- E. Thus, executing –D yarn.applicationmaster.reduce.tasks=2 will specify that the ApplicationMaster launch two task contains on the worker nodes.
- F. Developers specify reduce tasks in the exact same way for both MapReduce version 1 (MRv1) and MapReduce version 2 (MRv2) on YAR
- G. Thus, executing –D mapreduce.job.reduces-2 will specify reduce tasks.
- H. In YARN, resource allocation is function of virtual cores specified by the ApplicationManager making requests to the NodeManager where a reduce task is handeled by a single container (and thus a single virtual core). Thus, the developer needs to specify the number of virtual cores to the NodeManager by executing –p yarn.nodemanager.cpu-vcores=2
Answer: D
NEW QUESTION 8
You are running a Hadoop cluster with a NameNode on host mynamenode, a secondary NameNode on host mysecondarynamenode and several DataNodes.
Which best describes how you determine when the last checkpoint happened?
- A. Execute hdfs namenode –report on the command line and look at the Last Checkpoint information
- B. Execute hdfs dfsadmin –saveNamespace on the command line which returns to you the last checkpoint value in fstime file
- C. Connect to the web UI of the Secondary NameNode (http://mysecondary:50090/) and look at the “Last Checkpoint” information
- D. Connect to the web UI of the NameNode (http://mynamenode:50070) and look at the “Last Checkpoint” information
Answer: C
Explanation:
Reference:https://www.inkling.com/read/hadoop-definitive-guide-tom-white-3rd/chapter- 10/hdfs
NEW QUESTION 9
Your company stores user profile records in an OLTP databases. You want to join these records with web server logs you have already ingested into the Hadoop file system. What is the best way to obtain and ingest these user records?
- A. Ingest with Hadoop streaming
- B. Ingest using Hive’s IQAD DATA command
- C. Ingest with sqoop import
- D. Ingest with Pig’s LOAD command
- E. Ingest using the HDFS put command
Answer: C
NEW QUESTION 10
Assuming you’re not running HDFS Federation, what is the maximum number of NameNode daemons you should run on your cluster in order to avoid a “split-brain” scenario with your NameNode when running HDFS High Availability (HA) using Quorum- based storage?
- A. Two active NameNodes and two Standby NameNodes
- B. One active NameNode and one Standby NameNode
- C. Two active NameNodes and on Standby NameNode
- D. Unlimite
- E. HDFS High Availability (HA) is designed to overcome limitations on the number of NameNodes you can deploy
Answer: B
NEW QUESTION 11
You have installed a cluster HDFS and MapReduce version 2 (MRv2) on YARN. You have no dfs.hosts entry(ies) in your hdfs-site.xml configuration file. You configure a new worker node by setting fs.default.name in its configuration files to point to the NameNode on your cluster, and you start the DataNode daemon on that worker node. What do you have to do on the cluster to allow the worker node to join, and start sorting HDFS blocks?
- A. Without creating a dfs.hosts file or making any entries, run the commands hadoop.dfsadmin-refreshModes on the NameNode
- B. Restart the NameNode
- C. Creating a dfs.hosts file on the NameNode, add the worker Node’s name to it, then issue the command hadoop dfsadmin –refresh Nodes = on the Namenode
- D. Nothing; the worker node will automatically join the cluster when NameNode daemon is started
Answer: A
NEW QUESTION 12
Your cluster’s mapred-start.xml includes the following parameters
<name>mapreduce.map.memory.mb</name>
<value>4096</value>
<name>mapreduce.reduce.memory.mb</name>
<value>8192</value>
And any cluster’s yarn-site.xml includes the following parameters
<name>yarn.nodemanager.vmen-pmen-ration</name>
<value>2.1</value>
What is the maximum amount of virtual memory allocated for each map task before YARN will kill its Container?
- A. 4 GB
- B. 17.2 GB
- C. 8.9 GB
- D. 8.2 GB
- E. 24.6 GB
Answer: D
NEW QUESTION 13
Your cluster implements HDFS High Availability (HA). Your two NameNodes are named nn01 and nn02. What occurs when you execute the command: hdfs haadmin –failover nn01 nn02?
- A. nn02 is fenced, and nn01 becomes the active NameNode
- B. nn01 is fenced, and nn02 becomes the active NameNode
- C. nn01 becomes the standby NameNode and nn02 becomes the active NameNode
- D. nn02 becomes the standby NameNode and nn01 becomes the active NameNode
Answer: B
Explanation:
failover – initiate a failover between two NameNodes
This subcommand causes a failover from the first provided NameNode to the second. If the first
NameNode is in the Standby state, this command simply transitions the second to the Active statewithout error. If the first NameNode is in the Active state, an attempt will be made to gracefullytransition it to the Standby state. If this fails, the fencing methods (as configured bydfs.ha.fencing.methods) will be attempted in order until one of the methods succeeds. Only afterthis process will the second NameNode be transitioned to the Active state. If no fencing methodsucceeds, the second NameNode will not be transitioned to the Active state, and an error will bereturned.
NEW QUESTION 14
Which two are features of Hadoop’s rack topology?(Choose two)
- A. Configuration of rack awareness is accomplished using a configuration fil
- B. You cannot use a rack topology script.
- C. Hadoop gives preference to intra-rack data transfer in order to conserve bandwidth
- D. Rack location is considered in the HDFS block placement policy
- E. HDFS is rack aware but MapReduce daemon are not
- F. Even for small clusters on a single rack, configuring rack awareness will improve performance
Answer: BC
NEW QUESTION 15
Choose three reasons why should you run the HDFS balancer periodically?(Choose three)
- A. To ensure that there is capacity in HDFS for additional data
- B. To ensure that all blocks in the cluster are 128MB in size
- C. To help HDFS deliver consistent performance under heavy loads
- D. To ensure that there is consistent disk utilization across the DataNodes
- E. To improve data locality MapReduce
Answer: CDE
Explanation:
http://www.quora.com/Apache-Hadoop/It-is-recommended-that-you-run-the-HDFS-balancer-periodically-Why-Choose-3
NEW QUESTION 16
You are configuring a server running HDFS, MapReduce version 2 (MRv2) on YARN running Linux. How must you format underlying file system of each DataNode?
- A. They must be formatted as HDFS
- B. They must be formatted as either ext3 or ext4
- C. They may be formatted in any Linux file system
- D. They must not be formatted - - HDFS will format the file system automatically
Answer: B
NEW QUESTION 17
What two processes must you do if you are running a Hadoop cluster with a single NameNode and six DataNodes, and you want to change a configuration parameter so that it affects all six DataNodes.(Choose two)
- A. You must modify the configuration files on the NameNode onl
- B. DataNodes read their configuration from the master nodes
- C. You must modify the configuration files on each of the six SataNodes machines
- D. You don’t need to restart any daemon, as they will pick up changes automatically
- E. You must restart the NameNode daemon to apply the changes to the cluster
- F. You must restart all six DatNode daemon to apply the changes to the cluster
Answer: BD
NEW QUESTION 18
You are running a Hadoop cluster with MapReduce version 2 (MRv2) on YARN. You consistently see that MapReduce map tasks on your cluster are running slowly because of excessive garbage collection of JVM, how do you increase JVM heap size property to 3GB to optimize performance?
- A. yarn.application.child.java.opts=-Xsx3072m
- B. yarn.application.child.java.opts=-Xmx3072m
- C. mapreduce.map.java.opts=-Xms3072m
- D. mapreduce.map.java.opts=-Xmx3072m
Answer: C
Explanation:
Reference:http://hortonworks.com/blog/how-to-plan-and-configure-yarn-in-hdp-2-0/
NEW QUESTION 19
A slave node in your cluster has 4 TB hard drives installed (4 x 2TB). The DataNode is configured to store HDFS blocks on all disks. You set the value of the dfs.datanode.du.reserved parameter to 100 GB. How does this alter HDFS block storage?
- A. 25GB on each hard drive may not be used to store HDFS blocks
- B. 100GB on each hard drive may not be used to store HDFS blocks
- C. All hard drives may be used to store HDFS blocks as long as at least 100 GB in total is available on the node
- D. A maximum if 100 GB on each hard drive may be used to store HDFS blocks
Answer: B
NEW QUESTION 20
Which is the default scheduler in YARN?
- A. YARN doesn’t configure a default scheduler, you must first assign an appropriate scheduler class in yarn-site.xml
- B. Capacity Scheduler
- C. Fair Scheduler
- D. FIFO Scheduler
Answer: B
Explanation:
Reference:http://hadoop.apache.org/docs/r2.4.1/hadoop-yarn/hadoop-yarn-site/CapacityScheduler.html
NEW QUESTION 21
Which YARN daemon or service negotiations map and reduce Containers from the Scheduler, tracking their status and monitoring progress?
- A. NodeManager
- B. ApplicationMaster
- C. ApplicationManager
- D. ResourceManager
Answer: B
Explanation:
Reference:http://www.devx.com/opensource/intro-to-apache-mapreduce-2-yarn.html(See resource manager)
NEW QUESTION 22
Your cluster has the following characteristics:
✑ A rack aware topology is configured and on
✑ Replication is set to 3
✑ Cluster block size is set to 64MB
Which describes the file read process when a client application connects into the cluster and requests a 50MB file?
- A. The client queries the NameNode for the locations of the block, and reads all three copie
- B. The first copy to complete transfer to the client is the one the client reads as part of hadoop’s speculative execution framework.
- C. The client queries the NameNode for the locations of the block, and reads from the first location in the list it receives.
- D. The client queries the NameNode for the locations of the block, and reads from a random location in the list it receives to eliminate network I/O loads by balancing which nodes it retrieves data from any given time.
- E. The client queries the NameNode which retrieves the block from the nearest DataNode to the client then passes that block back to the client.
Answer: B
NEW QUESTION 23
Given:
You want to clean up this list by removing jobs where the State is KILLED. What command you enter?
- A. Yarn application –refreshJobHistory
- B. Yarn application –kill application_1374638600275_0109
- C. Yarn rmadmin –refreshQueue
- D. Yarn rmadmin –kill application_1374638600275_0109
Answer: B
Explanation:
Reference:http://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.1-latest/bk_using-apache-hadoop/content/common_mrv2_commands.html
NEW QUESTION 24
You are running Hadoop cluster with all monitoring facilities properly configured. Which scenario will go undeselected?
- A. HDFS is almost full
- B. The NameNode goes down
- C. A DataNode is disconnected from the cluster
- D. Map or reduce tasks that are stuck in an infinite loop
- E. MapReduce jobs are causing excessive memory swaps
Answer: B
NEW QUESTION 25
......
P.S. 2passeasy now are offering 100% pass ensure CCA-500 dumps! All CCA-500 exam questions have been updated with correct answers: https://www.2passeasy.com/dumps/CCA-500/ (60 New Questions)